- Sharding >
- Sharding Introduction
Sharding Introduction¶
On this page
Sharding is a method for storing data across multiple machines. MongoDB uses sharding to support deployments with very large data sets and high throughput operations.
Purpose of Sharding¶
Database systems with large data sets and high throughput applications can challenge the capacity of a single server. High query rates can exhaust the CPU capacity of the server. Larger data sets exceed the storage capacity of a single machine. Finally, working set sizes larger than the system’s RAM stress the I/O capacity of disk drives.
To address these issues of scales, database systems have two basic approaches: vertical scaling and sharding.
Vertical scaling adds more CPU and storage resources to increase capacity. Scaling by adding capacity has limitations: high performance systems with large numbers of CPUs and large amount of RAM are disproportionately more expensive than smaller systems. Additionally, cloud-based providers may only allow users to provision smaller instances. As a result there is a practical maximum capability for vertical scaling.
Sharding, or horizontal scaling, by contrast, divides the data set and distributes the data over multiple servers, or shards. Each shard is an independent database, and collectively, the shards make up a single logical database.
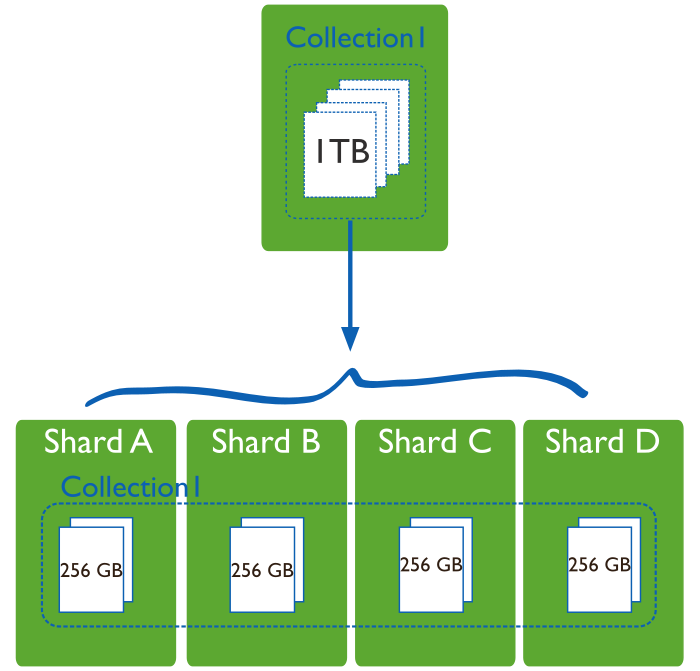
Sharding addresses the challenge of scaling to support high throughput and large data sets:
Sharding reduces the number of operations each shard handles. Each shard processes fewer operations as the cluster grows. As a result, a cluster can increase capacity and throughput horizontally.
For example, to insert data, the application only needs to access the shard responsible for that record.
Sharding reduces the amount of data that each server needs to store. Each shard stores less data as the cluster grows.
For example, if a database has a 1 terabyte data set, and there are 4 shards, then each shard might hold only 256GB of data. If there are 40 shards, then each shard might hold only 25GB of data.
Sharding in MongoDB¶
MongoDB supports sharding through the configuration of a sharded clusters.
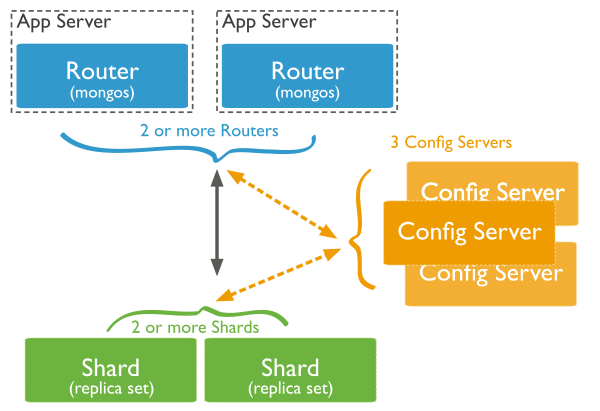
Sharded cluster has the following components: shards, query routers and config servers.
Shards store the data. To provide high availability and data consistency, in a production sharded cluster, each shard is a replica set [1]. For more information on replica sets, see Replica Sets.
Query Routers, or mongos instances, interface with client
applications and direct operations to the appropriate shard or
shards. The query router processes and targets operations to shards and then
returns results to the clients. A sharded cluster can contain more
than one query router to divide the client request load. A client sends
requests to one query router. Most sharded clusters have many query routers.
Config servers store the cluster’s metadata. This data contains a mapping of the cluster’s data set to the shards. The query router uses this metadata to target operations to specific shards. Production sharded clusters have exactly 3 config servers.
| [1] | For development and testing purposes
only, each shard can be a single mongod instead of a
replica set. Do not deploy production clusters without 3 config
servers. |
Data Partitioning¶
MongoDB distributes data, or shards, at the collection level. Sharding partitions a collection’s data by the shard key.
Shard Keys¶
To shard a collection, you need to select a shard key. A shard key is either an indexed field or an indexed compound field that exists in every document in the collection. MongoDB divides the shard key values into chunks and distributes the chunks evenly across the shards. To divide the shard key values into chunks, MongoDB uses either range based partitioning or hash based partitioning. See the Shard Key documentation for more information.
Range Based Sharding¶
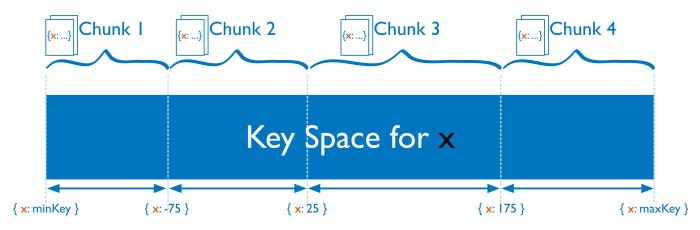
For range-based sharding, MongoDB divides the data set into ranges determined by the shard key values to provide range based partitioning. Consider a numeric shard key: If you visualize a number line that goes from negative infinity to positive infinity, each value of the shard key falls at some point on that line. MongoDB partitions this line into smaller, non-overlapping ranges called chunks where a chunk is range of values from some minimum value to some maximum value.
Given a range based partitioning system, documents with “close” shard key values are likely to be in the same chunk, and therefore on the same shard.
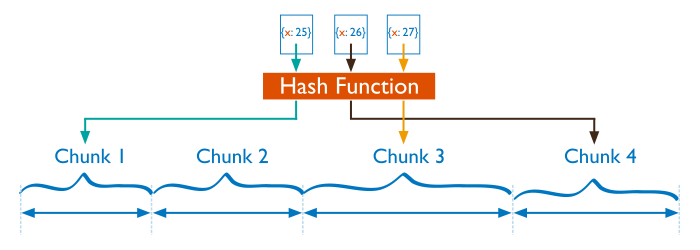
Hash Based Sharding¶
For hash based partitioning, MongoDB computes a hash of a field’s value, and then uses these hashes to create chunks.
With hash based partitioning, two documents with “close” shard key values are unlikely to be part of the same chunk. This ensures a more random distribution of a collection in the cluster.
Performance Distinctions between Range and Hash Based Partitioning¶
Range based partitioning supports more efficient range queries. Given a range query on the shard key, the query router can easily determine which chunks overlap that range and route the query to only those shards that contain these chunks.
However, range based partitioning can result in an uneven distribution of data, which may negate some of the benefits of sharding. For example, if the shard key is a linearly increasing field, such as time, then all requests for a given time range will map to the same chunk, and thus the same shard. In this situation, a small set of shards may receive the majority of requests and the system would not scale very well.
Hash based partitioning, by contrast, ensures an even distribution of data at the expense of efficient range queries. Hashed key values results in random distribution of data across chunks and therefore shards. But random distribution makes it more likely that a range query on the shard key will not be able to target a few shards but would more likely query every shard in order to return a result.
Customized Data Distribution with Tag Aware Sharding¶
MongoDB allows administrators to direct the balancing policy using tag aware sharding. Administrators create and associate tags with ranges of the shard key, and then assign those tags to the shards. Then, the balancer migrates tagged data to the appropriate shards and ensures that the cluster always enforces the distribution of data that the tags describe.
Tags are the primary mechanism to control the behavior of the balancer and the distribution of chunks in a cluster. Most commonly, tag aware sharding serves to improve the locality of data for sharded clusters that span multiple data centers.
See Tag Aware Sharding for more information.
Maintaining a Balanced Data Distribution¶
The addition of new data or the addition of new servers can result in data distribution imbalances within the cluster, such as a particular shard contains significantly more chunks than another shard or a size of a chunk is significantly greater than other chunk sizes.
MongoDB ensures a balanced cluster using two background process: splitting and the balancer.
Splitting¶
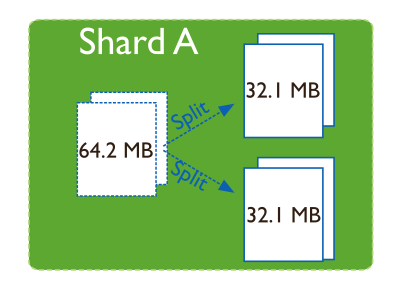
Splitting is a background process that keeps chunks from growing too large. When a chunk grows beyond a specified chunk size, MongoDB splits the chunk in half. Inserts and updates triggers splits. Splits are an efficient meta-data change. To create splits, MongoDB does not migrate any data or affect the shards.
Balancing¶
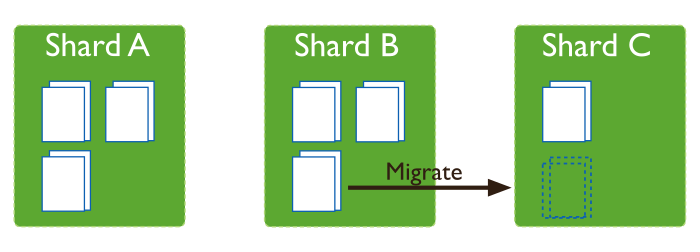
The balancer is a background process that manages chunk migrations. The balancer can run from any of the query routers in a cluster.
When the distribution of a sharded collection in a cluster is uneven,
the balancer process migrates chunks from the shard that has the
largest number of chunks to the shard with the least number of chunks
until the collection balances. For example: if collection users
has 100 chunks on shard 1 and 50 chunks on shard 2, the balancer
will migrate chunks from shard 1 to shard 2 until the collection
achieves balance.
The shards manage chunk migrations as a background operation between an origin shard and a destination shard. During a chunk migration, the destination shard is sent all the current documents in the chunk from the origin shard. Next, the destination shard captures and applies all changes made to the data during the migration process. Finally, the metadata regarding the location of the chunk on config server is updated.
If there’s an error during the migration, the balancer aborts the process leaving the chunk unchanged on the origin shard. MongoDB removes the chunk’s data from the origin shard after the migration completes successfully.
Adding and Removing Shards from the Cluster¶
Adding a shard to a cluster creates an imbalance since the new shard has no chunks. While MongoDB begins migrating data to the new shard immediately, it can take some time before the cluster balances.
When removing a shard, the balancer migrates all chunks from a shard to other shards. After migrating all data and updating the meta data, you can safely remove the shard.