- Aggregation >
- Aggregation Introduction
Aggregation Introduction¶
On this page
Aggregations are operations that process data records and return
computed results. MongoDB provides a rich set of aggregation
operations that examine and perform calculations on the data sets.
Running data aggregation on the mongod instance simplifies
application code and limits resource requirements.
Like queries, aggregation operations in MongoDB use collections of documents as an input and return results in the form of one or more documents.
Aggregation Modalities¶
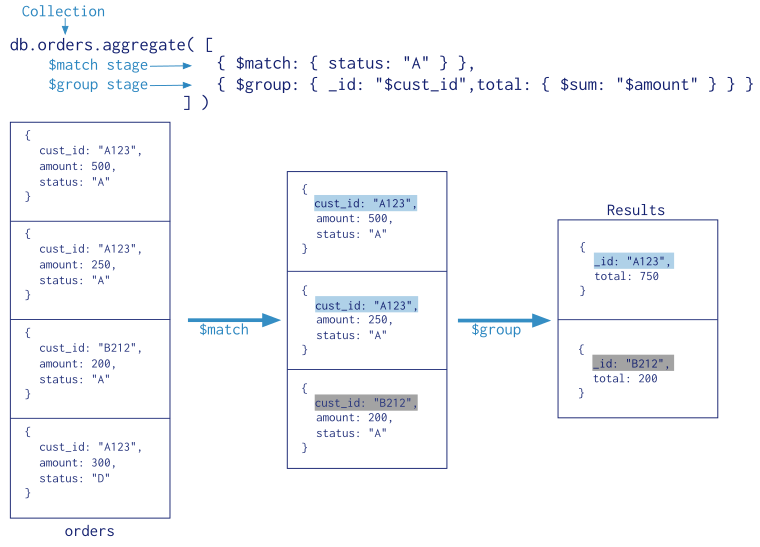
Aggregation Pipelines¶
MongoDB 2.2 introduced a new aggregation framework, modeled on the concept of data processing pipelines. Documents enter a multi-stage pipeline that transforms the documents into an aggregated result.
The most basic pipeline stages provide filters that operate like queries and document transformations that modify the form of the output document.
Other pipeline operations provide tools for grouping and sorting documents by specific field or fields as well as tools for aggregating the contents of arrays, including arrays of documents. In addition, pipeline stages can use operators for tasks such as calculating the average or concatenating a string.
The pipeline provides efficient data aggregation using native operations within MongoDB, and is the preferred method for data aggregation in MongoDB.
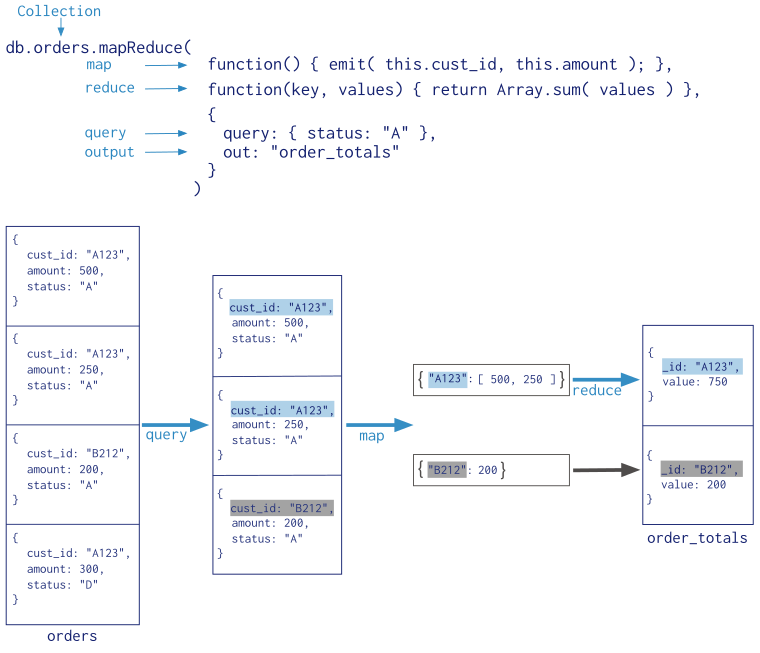
Map-Reduce¶
MongoDB also provides map-reduce operations to perform aggregation. In general, map-reduce operations have two phases: a map stage that processes each document and emits one or more objects for each input document, and reduce phase that combines the output of the map operation. Optionally, map-reduce can have a finalize stage to make final modifications to the result. Like other aggregation operations, map-reduce can specify a query condition to select the input documents as well as sort and limit the results.
Map-reduce uses custom JavaScript functions to perform the map and reduce operations, as well as the optional finalize operation. While the custom JavaScript provide great flexibility compared to the aggregation pipeline, in general, map-reduce is less efficient and more complex than the aggregation pipeline.
Note
Starting in MongoDB 2.4, certain mongo shell
functions and properties are inaccessible in map-reduce
operations. MongoDB 2.4 also provides support for multiple
JavaScript operations to run at the same time. Before MongoDB 2.4,
JavaScript code executed in a single thread, raising concurrency
issues for map-reduce.
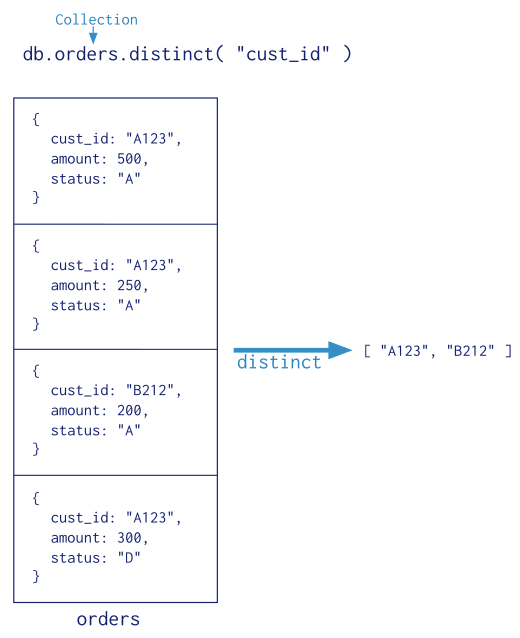
Single Purpose Aggregation Operations¶
For a number of common single purpose aggregation operations, MongoDB provides special purpose database commands. These common aggregation operations are: returning a count of matching documents, returning the distinct values for a field, and grouping data based on the values of a field. All of these operations aggregate documents from a single collection. While these operations provide simple access to common aggregation processes, they lack the flexibility and capabilities of the aggregation pipeline and map-reduce.
Additional Features and Behaviors¶
Both the aggregation pipeline and map-reduce can operate on a sharded collection. Map-reduce operations can also output to a sharded collection. See Aggregation Pipeline and Sharded Collections and Map-Reduce and Sharded Collections for details.
The aggregation pipeline can use indexes to improve its performance during some of its stages. In addition, the aggregation pipeline has an internal optimization phase. See Pipeline Operators and Indexes and Aggregation Pipeline Optimization for details.
For a feature comparison of the aggregation pipeline, map-reduce, and the special group functionality, see Aggregation Commands Comparison.