- Indexes >
- Index Concepts >
- Index Types >
- Single Field Indexes
Single Field Indexes¶
MongoDB provides complete support for indexes on any field in a collection of documents. By default, all collections have an index on the _id field, and applications and users may add additional indexes to support important queries and operations.
MongoDB supports indexes that contain either a single field or multiple fields depending on the operations that this index-type supports. This document describes ascending/descending indexes that contain a single field. Consider the following illustration of a single field index.
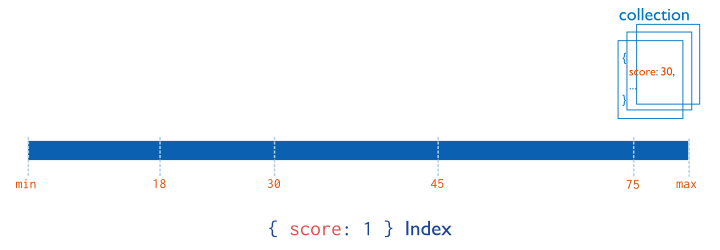
See also
Compound Indexes for information about indexes that include multiple fields, and Index Introduction for a higher level introduction to indexing in MongoDB.
Example¶
Given the following document in the friends collection:
The following command creates an index on the name field:
Cases¶
_id Field Index¶
MongoDB creates the _id index, which is an ascending unique
index on the _id field, for all collections when
the collection is created. You cannot remove the index on the _id
field.
Think of the _id field as the primary key for a collection.
Every document must have a unique _id field. You may store any
unique value in the _id field. The default value of _id is an
ObjectId which is generated when the client inserts the document. An
ObjectId is a 12-byte unique identifier suitable for use
as the value of an _id field.
Note
In sharded clusters, if you do not use
the _id field as the shard key, then your application
must ensure the uniqueness of the values in the _id field
to prevent errors. This is most-often done by using a standard
auto-generated ObjectId.
Before version 2.2, capped collections
did not have an _id field. In version 2.2 and newer, capped
collections do have an _id field, except those in the local
database. See Capped Collections Recommendations
and Restrictions
for more information.
Indexes on Embedded Fields¶
You can create indexes on fields within embedded documents, just as you
can index top-level fields in documents. Indexes on embedded fields
differ from indexes on embedded documents,
which include the full content up to the maximum index size of the embedded document in the index. Instead, indexes on
embedded fields allow you to use a “dot notation,” to introspect into
embedded documents.
Consider a collection named people that holds documents that resemble
the following example document:
You can create an index on the address.zipcode field, using the
following specification:
Indexes on Embedded Documents¶
You can also create indexes on embedded documents.
For example, the factories collection contains documents that
contain a metro field, such as:
The metro field is an embedded document, containing the embedded fields
city and state. The following command creates an index on the metro
field as a whole:
The following query can use the index on the metro field:
This query returns the above document. When performing equality matches on embedded documents, field order matters and the embedded documents must match exactly. For example, the following query does not match the above document:
See Query Embedded Documents for more information regarding querying on embedded documents.