- Aggregation >
- Aggregation Concepts >
- Aggregation Pipeline
Aggregation Pipeline¶
On this page
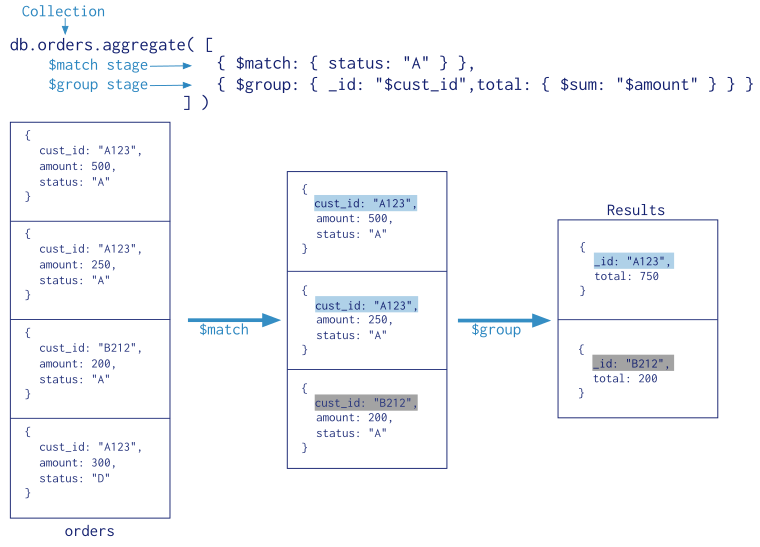
The aggregation pipeline is a framework for data aggregation modeled on the concept of data processing pipelines. Documents enter a multi-stage pipeline that transforms the documents into aggregated results.
The aggregation pipeline provides an alternative to map-reduce and may be the preferred solution for aggregation tasks where the complexity of map-reduce may be unwarranted.
Aggregation pipeline have some limitations on value types and result size. See Aggregation Pipeline Limits for details on limits and restrictions on the aggregation pipeline.
Pipeline¶
The MongoDB aggregation pipeline consists of stages. Each stage transforms the documents as they pass through the pipeline. Pipeline stages do not need to produce one output document for every input document; e.g., some stages may generate new documents or filter out documents. Pipeline stages can appear multiple times in the pipeline.
MongoDB provides the db.collection.aggregate() method in the
mongo shell and the aggregate command for
aggregation pipeline. See
Stage Operators for the available stages.
For example usage of the aggregation pipeline, consider Aggregation with User Preference Data and Aggregation with the Zip Code Data Set.
Pipeline Expressions¶
Some pipeline stages takes a pipeline expression as its operand. Pipeline expressions specify the transformation to apply to the input documents. Expressions have a document structure and can contain other expression.
Pipeline expressions can only operate on the current document in the pipeline and cannot refer to data from other documents: expression operations provide in-memory transformation of documents.
Generally, expressions are stateless and are only evaluated when seen by the aggregation process with one exception: accumulator expressions.
The accumulators, used with the $group pipeline operator,
maintain their state (e.g. totals, maximums, minimums, and related
data) as documents progress through the pipeline.
For more information on expressions, see Expressions.
Aggregation Pipeline Behavior¶
In MongoDB, the aggregate command operates on a single
collection, logically passing the entire collection into the
aggregation pipeline. To optimize the operation, wherever possible, use
the following strategies to avoid scanning the entire collection.
Pipeline Operators and Indexes¶
The $match and $sort pipeline operators can
take advantage of an index when they occur at the beginning of the
pipeline.
New in version 2.4: The $geoNear pipeline operator takes advantage of a
geospatial index. When using $geoNear, the
$geoNear pipeline operation must appear as the first
stage in an aggregation pipeline.
Even when the pipeline uses an index, aggregation still requires access to the actual documents; i.e. indexes cannot fully cover an aggregation pipeline.
Changed in version 2.6: In previous versions, for very select use cases, an index could cover a pipeline.
Early Filtering¶
If your aggregation operation requires only a subset of the data in a
collection, use the $match, $limit, and
$skip stages to restrict the documents that enter at the
beginning of the pipeline. When placed at the beginning of a pipeline,
$match operations use suitable indexes to scan only
the matching documents in a collection.
Placing a $match pipeline stage followed by a
$sort stage at the start of the pipeline is logically
equivalent to a single query with a sort and can use an index. When
possible, place $match operators at the beginning of the
pipeline.
Additional Features¶
The aggregation pipeline has an internal optimization phase that provides improved performance for certain sequences of operators. For details, see Aggregation Pipeline Optimization.
The aggregation pipeline supports operations on sharded collections. See Aggregation Pipeline and Sharded Collections.