- Indexes >
- Index Introduction
Index Introduction¶
On this page
Indexes support the efficient execution of queries in MongoDB. Without
indexes MongoDB must scan every document in a collection to select
those documents that match the query statement. These collection
scans are inefficient because they require mongod to
process a larger volume of data than an index for each operation.
Indexes are special data structures [1] that store a small portion of the collection’s data set in an easy to traverse form. The index stores the value of a specific field or set of fields, ordered by the value of the field.
Fundamentally, indexes in MongoDB are similar to indexes in other database systems. MongoDB defines indexes at the collection level and supports indexes on any field or sub-field of the documents in a MongoDB collection.
If an appropriate index exists for a query, MongoDB can use the index to limit the number of documents it must inspect. In some cases, MongoDB can use the data from the index to determine which documents match a query. The following diagram illustrates a query that selects documents using an index.
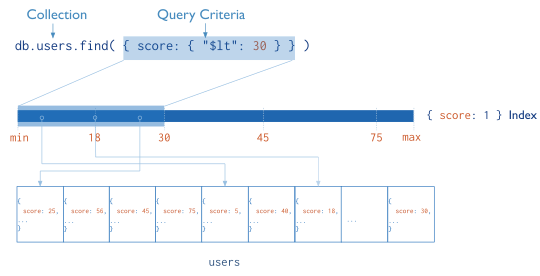
| [1] | MongoDB indexes use a B-tree data structure. |
Optimization¶
Consider the documentation of the query optimizer for more information on the relationship between queries and indexes.
Create indexes to support common and user-facing queries. Having these indexes will ensure that MongoDB only scans the smallest possible number of documents.
Indexes can also optimize the performance of other operations in specific situations:
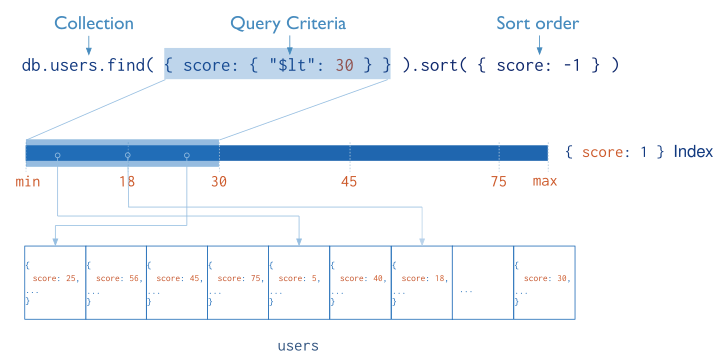
Sorted Results¶
MongoDB can use indexes to return documents sorted by the index key directly from the index without requiring an additional sort phase.
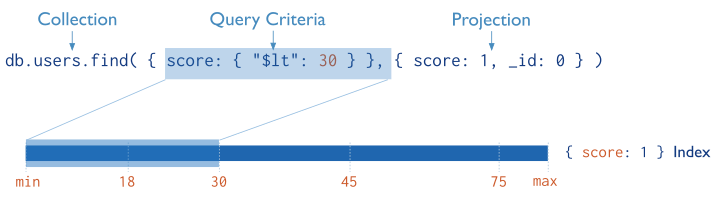
Covered Results¶
When the query criteria and the projection of a query include only the indexed fields, MongoDB will return results directly from the index without scanning any documents or bringing documents into memory. These covered queries can be very efficient. Indexes can also cover aggregation pipeline operations.
Index Types¶
MongoDB provides a number of different index types to support specific types of data and queries.
Default _id¶
All MongoDB collections have an index on the _id field that exists
by default. If applications do not specify a value for _id the
driver or the mongod will create an _id field with an
ObjectId value.
The _id index is unique, and prevents clients from inserting two
documents with the same value for the _id field.
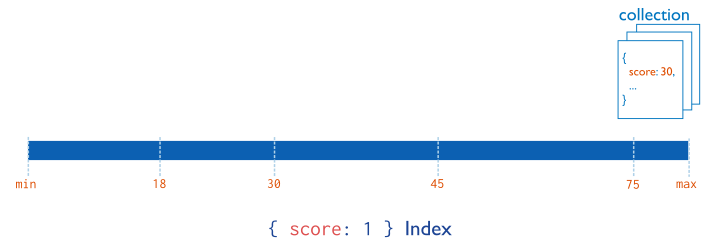
Single Field¶
In addition to the MongoDB-defined _id index, MongoDB supports
user-defined indexes on a single field of a document. Consider the following illustration of a
single-field index:
Compound Index¶
MongoDB also supports user-defined indexes on multiple fields. These
compound indexes behave like single-field
indexes; however, the query can select documents based on additional
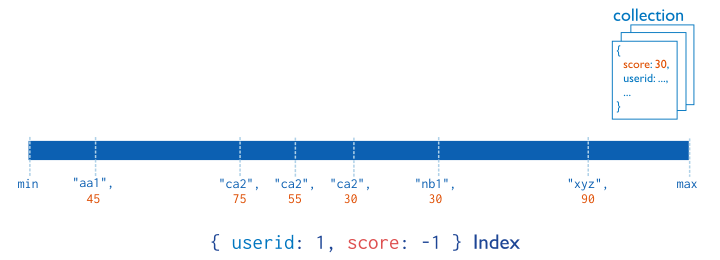
fields. The order of fields listed in a compound index has
significance. For instance, if a compound index consists of { userid:
1, score: -1 }, the index sorts first by userid and then, within
each userid value, sort by score. Consider the following
illustration of this compound index:
Multikey Index¶
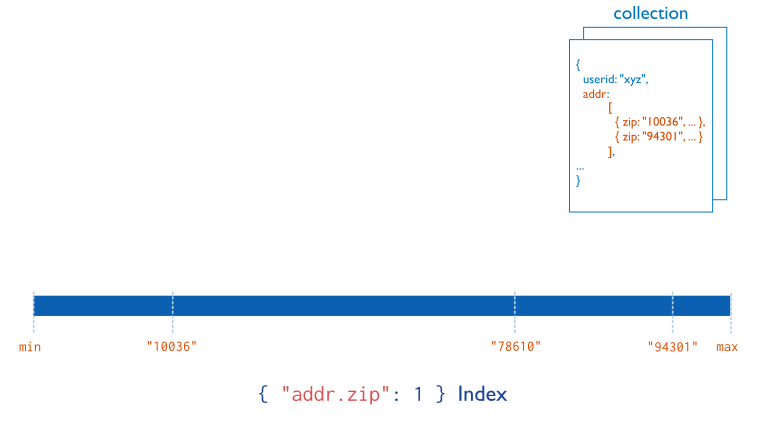
MongoDB uses multikey indexes to index the content stored in arrays. If you index a field that holds an array value, MongoDB creates separate index entries for every element of the array. These multikey indexes allow queries to select documents that contain arrays by matching on element or elements of the arrays. MongoDB automatically determines whether to create a multikey index if the indexed field contains an array value; you do not need to explicitly specify the multikey type.
Consider the following illustration of a multikey index:
Geospatial Index¶
To support efficient queries of geospatial coordinate data, MongoDB provides two special indexes: 2d indexes that uses planar geometry when returning results and 2sphere indexes that use spherical geometry to return results.
See 2d Index Internals for a high level introduction to geospatial indexes.
Text Indexes¶
MongoDB provides a beta text index type that supports searching
for string content in a collection. These text indexes do not store
language-specific stop words (e.g. “the”, “a”, “or”) and stem the
words in a collection to only store root words.
See Text Indexes for more information on text indexes and search.
Hashed Indexes¶
To support hash based sharding, MongoDB provides a hashed index type, which indexes the hash of the value of a field. These indexes have a more random distribution of values along their range, but only support equality matches and cannot support range-based queries.
Index Properties¶
Unique Indexes¶
The unique property for an index causes MongoDB to reject duplicate values for the indexed field. To create a unique index on a field that already has duplicate values, see Drop Duplicates for index creation options. Other than the unique constraint, unique indexes are functionally interchangeable with other MongoDB indexes.
Sparse Indexes¶
The sparse property of an index ensures that the index only contain entries for documents that have the indexed field. The index skips documents that do not have the indexed field.
You can combine the sparse index option with the unique index option to reject documents that have duplicate values for a field but ignore documents that do not have the indexed key.